
- Part II, of the Mass Mailer integration series, see also:
Architecture and Review
Overview
Introduction
In this section we’ll try to lay some basic architecture of our demo application. And I’ll try to explain why I’ve opted for certain choices.
If you just want to get started with the app, feel free to jump ahead to Part III. Which contains some explanation around the implementation as well as links to the source.
In a future version I’ll place a trial version online with dummy-data. For now I hope the video and the source will be all you need to get this setup on your end. Or at the very least provide you with a basis to further build out and improve upon.
Same disclaimer apriori: It’s a demo implementation. With the goal of explaining and demonstrating the main principles. It’s very light on error checking, and not production ready.
Integration Requirements
Let’s write down a cursory set of requirement for our app.
Functional requirements
- A master database that we control, that contains all leads of all time.
- Leads in our dbase have accurate up to date status with regards to any campaigns and mass mailing services they have been involved with.
- Ability to select and load a sub-selection of leads into a mass mailing platform of our choice. ( In this case MailOctopus)
- Ability to fetch all existing campaigns from our mailing platform, and update all campaign leads in our database with the results of the campaign.
- Automatically create new leads, enriched with all relevant data available in our dbase in Salesforce for all emails that show they were opened, or received click through.
Non functional requirements
- Database under direct control. Hence no (practical) extra costs for additional storage, number of queries, procedures or amount of replicas.
- No software cost. We only use open source alternatives, with a proven track-record, that have seen years, sometimes decades of real-life business use, with some of the biggest e-businesses on the planet. (* Exceptions are of course the connecting systems like Salesforce).
- Easy to scale and deploy. (* This isn’t really an issue for this type of app, but in case you want to scale to a million+ concurrent users, you can.)
Application architecture
A high level diagram of the core components:
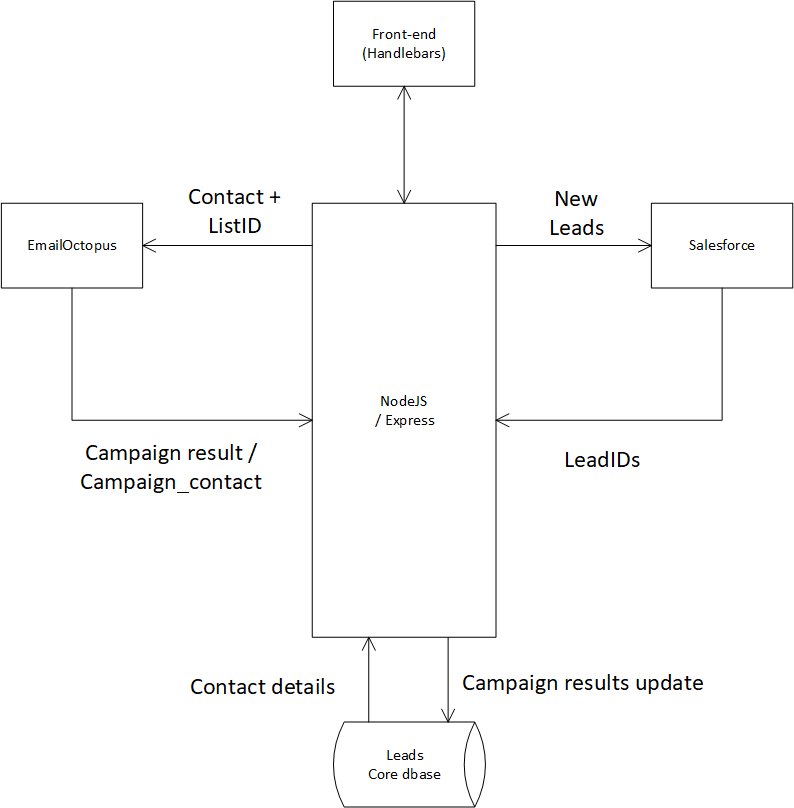
As can be inferred from our drawing, we’re using NodeJS with Express as the middleware to connect all the separate parts of our application. Hence the NodeJS / Express server handles all network comms. Variable and object translations, and other tid-bits that are generally expected of the middleware.
There’s an infinite amount of variations that are currently employed around this core setup. ( E.g. Typescript implementations with PRISM object mapping and NESTJS , etc etc). I went with NodeJS as I think it has the highest amount of years under it’s belt in terms of business use and experience. And the tremendous wealth of documentation that can be found everywhere. But of course you should pick whatever takes your fancy. Most components of this are app easily interchanged, or mutated into some related stack. It’s just one way to solve a problem.
Node/Express handle all middleware related functions, as well as server side templates we’ll employ for the front-end.
To ORM or not to ORM
For the sake of brevity and for educational properties, we opted out of an ORM. But this might be something you’d like to introduce in case you intend to build a ‘production’ application. While it adds some complexity, it reduces the added work whenever you want to modify the relevant fields used by the application.
UI
The templating is handled by handlebars. Again nothing spectacular, but more then sufficient for our modest UI needs. We use pre-compiled templates for different tables to dynamically refresh page data. This is a neat trick handlebars offers in case you want to stick to server sided templates. You’re alternative route would be to go with a framework like REACT or VUE.
Databases
Since our non-functional requirements stated all off-shelve components should be free ! We are left with . . . actually a shocking abundance of choices.
MongoDB , MySQL, etc et. The list of rather decent open source databases is something to behold. Not being too much of an adventurer the main decision to make for me, was Relational or Document database. I opted for Relational as it seems to fit the structure of our application well. In terms of performance I doubt one or the other will make much difference, so pick what you like. I went with Postgresql, as I feel it’s a mature, business ready, very well maintained, excellent RDBMS. Postgres is an absolute monster of a DBMS. This comes with some downsides. Be ready to wrestle with some idiosyncratic SQL implementations etc. But alas, I’m not all that familiar with it’s peculiarities. So that’s probably just the inexperience talking.
The ERD chosen for this implementation:
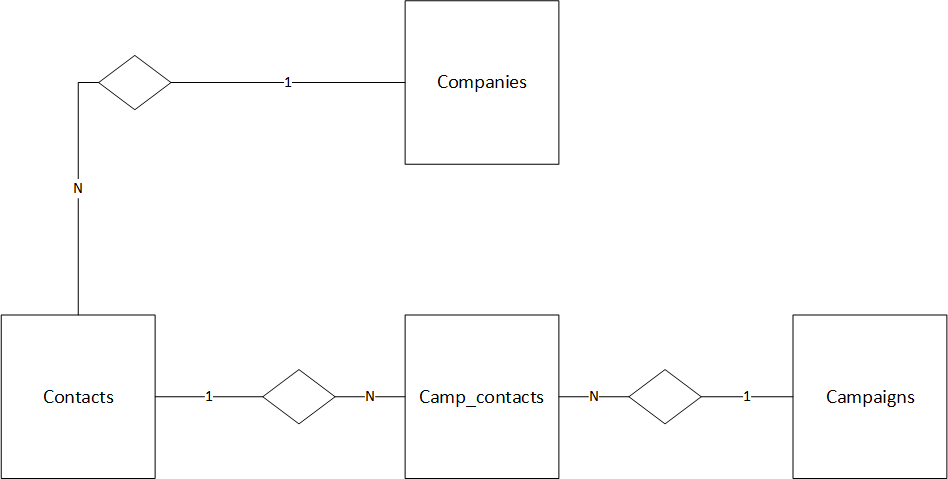
But if you’re used to simply storing some sort of object on-the-fly in Mongo without a second thought to table definitions and object structure etc. , get ready for some hair pulling
The upside is the seemingly inexhaustible performance and ease with which it handles volume. ( Try slowing it down with some big queries or something to that extend, my guess is you’d be surprised) . So in case you have a couple million leads, the dbase is probably not going to be your bottleneck. This thing will beat up your fancy SaaS / PaaS platforms all night and all day while barely even breaking a sweat.
All relevant queries for this implementation can be found in the code. So hopefully that will reduce the hair pulling a bit. And provide enough of a basis to build out.
Integration Technical Overview
Here I’ll briefly iterate over the main NPM packages we use to establish connectivity between our adjacent platforms.
In our previous application architecture drawing, we illustrated the following main interfaces:
- NodeJS – Postgresql
- NodeJS – MailOctopus
- NodeJS – Salesforce
- NodeJS – Front-end
In this case NodeJS functions as middleware. Of course you could swap it out for something more corporate ( like Boomi or WebMethods , etc) but that would violate our non-functional requirements. And if you’re not running a sizeable budget, it will definitely violate your liquidity.
- We use the standard pg.js package. Which will provide us with connectivity, and a window to execute our queries through. It’s very bare-bones, as such it will provide maximum freedom for your chosen implementation model
- The octopus provides a standard REST API to interact with. It’s very user friendly, and we only need to implement a Bearer token for connectivity. Which makes this a very straightforward connection. To handle server to server comms we utilize Axios which is currently one of the most used client wrapper libraries in use. It’s well documented and has an extensive featureset (which we don’t need, but hey, it’s nice it’s there)
- For Salesforce interactivity, JSForce was used. Again a very straightforward package that has been on NPM for several years. It allows for bearer type authentication. Although you could utilize an OAuth2 authentication flow as well, if so desired. In this app we’ll stick to bearer tokens for simplicity.
- For the front-end Handlebars is used, while a server side template, it has some neat features like the pre-compiled template, this allows us to dynamically load tables with the latest query / app data without unnecessary page reloads. Hence we’re able to keep the entire app server templated. With a light web client.
Design Choices
Most choices were hopefully clarified in the previous sections. Lastly we want to mention the choice to run the dbase in a docker container. This allows for portability, and replication without too much involvement. Hence the entire application could be dockerized with 2 containers. While allowing for the freedom to scale in case the need arises. Again, for this type of application that seems unlikely. The other choices were made based on the need to minimize costs and keep full control.
Will running the dbase container be more involved then utilizing a hosted Postgresql instance ? yes, of course. But depending on your company size and budget the effort might be worth the reduction is cost. Especially once you go into large numbers of leads.
Personally I don’t want some ominous sense that for every query I run I’ll receive a line item on my bill.
The latter is something we’ll revisit in some articles in the future. But by the logic of Dilbert, it’s only natural to see a movement of at least partial in-sourcing of certain apps / functionalities. As some organisations are slowly starting to experience how those elaborate pricing models work in practice.